Imagic: Text-Based Real Image Editing with Diffusion Models
Imagic edits a single real-world image using a target text prompt. It can apply complex non-rigid changes.
arXiv | PDF
Abstract
Text-conditioned image editing has recently attracted considerable interest. However, most methods are currently either limited to specific editing types (e.g., object overlay, style transfer), or apply to synthetically generated images, or require multiple input images of a common object. In this paper we demonstrate, for the very first time, the ability to apply complex (e.g., non-rigid) text-guided semantic edits to a single real image. For example, we can change the posture and composition of one or multiple objects inside an image, while preserving its original characteristics. Our method can make a standing dog sit down or jump, cause a bird to spread its wings, etc. — each within its single high-resolution natural image provided by the user. Contrary to previous work, our proposed method requires only a single input image and a target text (the desired edit). It operates on real images, and does not require any additional inputs (such as image masks or additional views of the object). Our method, which we call "Imagic", leverages a pre-trained text-to-image diffusion model for this task. It produces a text embedding that aligns with both the input image and the target text, while fine-tuning the diffusion model to capture the image-specific appearance. We demonstrate the quality and versatility of our method on numerous inputs from various domains, showcasing a plethora of high quality complex semantic image edits, all within a single unified framework.
Additional Examples


"A wooden chair" |
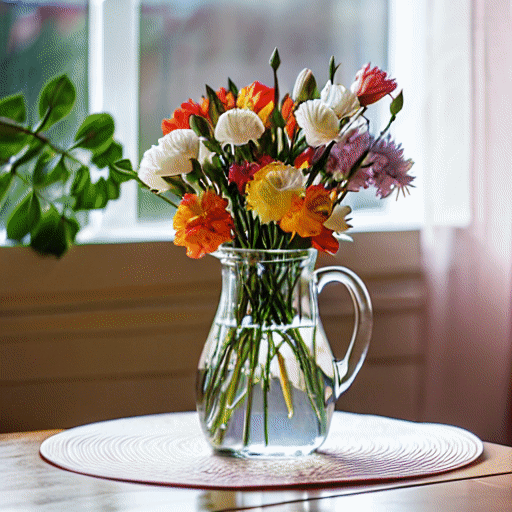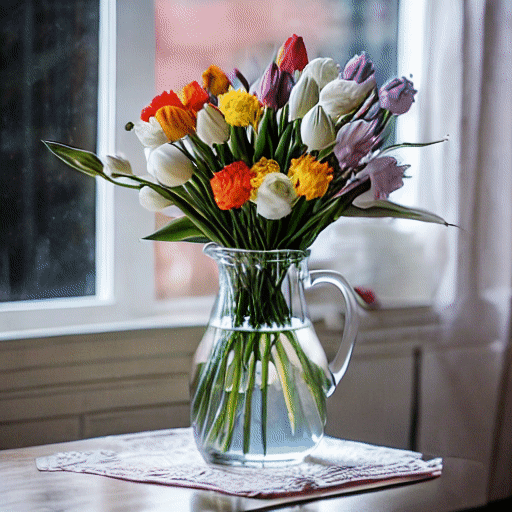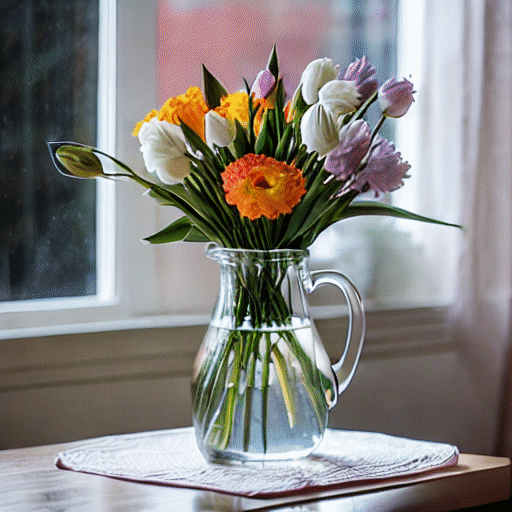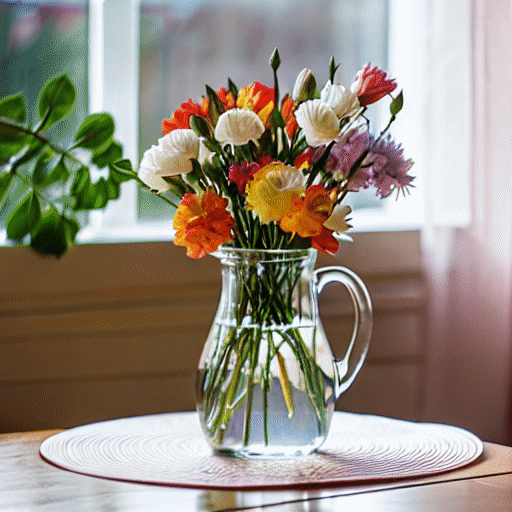
"A vase of colorful tulips" |

"A white wedding cake" |
Method
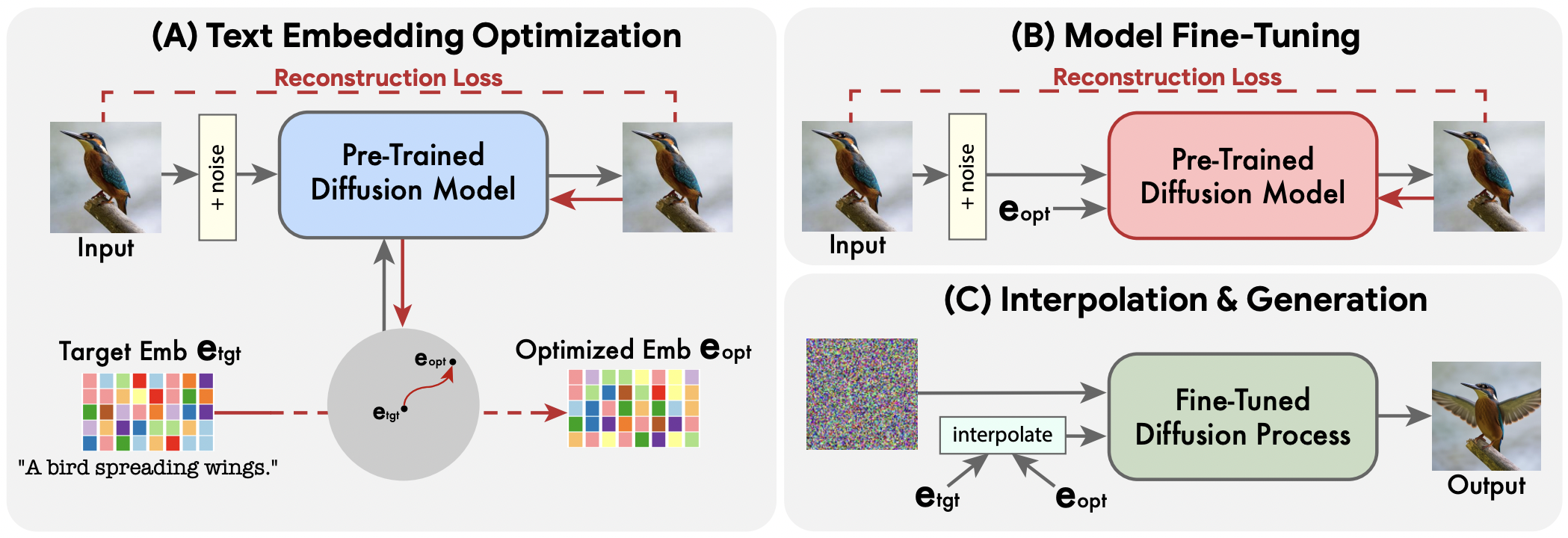
Given a real image and a target text prompt, we encode the target text and get the initial text embedding \(e_{tgt}\), then optimize it to reconstruct the input image, obtaining \(e_{opt}\). We then fine-tune the generative model to improve fidelity to the input image while fixing \(e_{opt}\). Finally, we interpolate \(e_{opt}\) with \(e_{tgt}\) to generate the edit result.
TEdBench
We introduce
TEdBench (Textual Editing Benchmark), a novel collection of 100 pairs of input images and target texts describing a desired complex non-rigid edit. We hope that future research will benefit from TEdBench as a standardized evaluation set for this task. To that end, we make TEdBench publicly available, along with Imagic's results to allow for comparisons.
 | TEdBench |
 | TEdBench |
Paper
 |
"Imagic: Text-Based Real Image Editing with Diffusion Models",
Bahjat Kawar*, Shiran Zada*, Oran Lang, Omer Tov, Huiwen Chang, Tali Dekel, Inbar Mosseri, and Michal Irani.
Conference on Computer Vision and Pattern Recognition (CVPR) 2023
[PDF]
|
BibTeX
@inproceedings{kawar2023imagic,
title={Imagic: Text-Based Real Image Editing with Diffusion Models},
author={Kawar, Bahjat and Zada, Shiran and Lang, Oran and Tov, Omer and Chang, Huiwen and Dekel, Tali and Mosseri, Inbar and Irani, Michal},
booktitle={Conference on Computer Vision and Pattern Recognition 2023},
year={2023}
}




















